
RAG Explained: How Retrieval-Augmented Generation Works and When You Actually Need It
RAG (retrieval-augmented generation) gives an LLM an open book — retrieving the right document at the moment it’s needed, instead of guessing from training memory. Here’s how it works, with a real example from a health equipment system in Malawi.
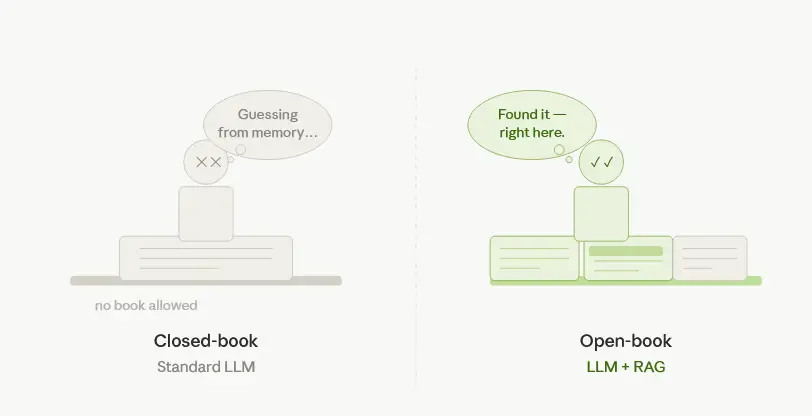
Picture two students sitting the same exam.
The first studied hard, memorised everything they could, and walked in with nothing but a pen. On the day, they answered from memory — confident where their knowledge was strong, guessing where it had gaps, and occasionally wrong in the most convincing way possible. They had no way to check.
The second student sat an open-book version. Same intelligence, same preparation — but when the question came up about the specific regulation amended in 2023, they flipped to the right page, read the relevant paragraph, and answered accurately. No guessing. No outdated information confidently stated as fact.
That is the difference between an LLM on its own and an LLM with RAG.
A standard language model — GPT-4, Claude, Gemini, whatever you’re using — is the closed-book student. Everything it knows was baked in during training. It cannot know what happened after that training ended, and it cannot know what is in your internal documents, your project reports, your product manuals. When you ask it something outside that boundary, it either says it doesn’t know or, more dangerously, it makes something up that sounds plausible.
RAG — retrieval-augmented generation — gives the model an open book. At the moment a question is asked, the system retrieves the most relevant documents from your own knowledge base and hands them to the model along with the question. The model reads both and answers from what it actually retrieved, not from what it vaguely remembers.
One line summary: RAG is how you give an AI model an open book.
The Problem That Made Me Take RAG Seriously
A few years ago I was part of a project with the Ministry of Health in Malawi and PATH — an international global health organisation — building a system called MEMIS: the Medical Equipment Management Information System. Its job was to help government hospitals manage their medical equipment. Asset registers, maintenance schedules, fault histories, service records, warranty tracking — all of it in one place across public health facilities around the country.
Every piece of medical equipment — X-ray machines, autoclaves, oxygen concentrators, anaesthesia units, theatre lights, patient monitors — comes with documentation. Manufacturer manuals, calibration certificates, operating licences, service bulletins, spare parts catalogues. Some of it is fifty pages. Some is three hundred. Some is in English, some in the original language of the manufacturer. Now multiply that across hundreds of hospitals and clinics, across dozens of equipment categories, across equipment purchased over the span of two decades.
You end up with thousands of documents. Most of them sitting in folders nobody opens unless there is a problem.
Here is the scenario that stuck with me: a biomedical technician at a district hospital needs to know the correct sterilisation cycle pressure for a specific autoclave model — during a procedure, not at their desk. They need that answer in thirty seconds. What do they actually do? They search a shared drive. They scroll through a PDF. They call a colleague who might remember. They guess.
That gap — between having the information and being able to retrieve it usefully, in the moment it is needed — is exactly what RAG is built to close.
MEMIS did not implement RAG. The project was focused on the core management system, and the technology was not as accessible then as it is today. But I have thought about it since. Because the problem was real: thousands of critical documents, and no intelligent way to ask them a question.
If I were building MEMIS today, RAG would not be optional.
How RAG Actually Works
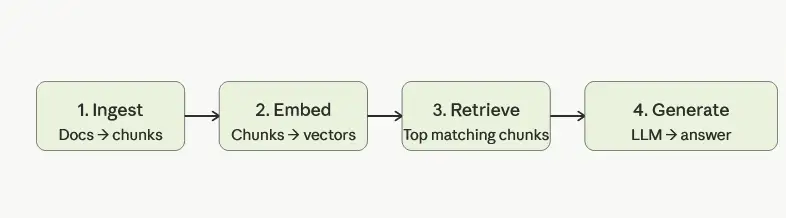
The mechanics are straightforward once you see them laid out. It essentially happens in four movements:
- Preparing the data (Ingestion): Your documents are processed and broken into chunks—paragraphs, sections, or fixed-length passages depending on the content type. Each chunk is then converted into a vector: a list of numbers that mathematically represents the meaning of that text. This is done by an embedding model. The resulting vectors are stored in a vector database alongside the original text.
- Making it searchable (Indexing): The vector database indexes all those chunks so they can be searched by meaning, not just by exact keyword. This is the critical difference from a normal search. If a technician asks “what is the maximum operating temperature for this analyser,” the system finds the right paragraph even if that paragraph uses the words “upper thermal limit” or “do not exceed 35°C.” Semantic search understands intent, not just strings.
- Fetching the right page (Retrieval): When a user submits a question, that question is also converted into a vector by the same embedding model. The database then returns the most semantically similar chunks from across all your indexed documents — typically the top three to five most relevant passages. These are the “pages” the open-book student flips to.
- Drafting the answer (Generation): Those retrieved chunks are passed to the LLM alongside the original question. The prompt looks something like: “Answer the question below using only the context provided. Do not use outside knowledge.” The model reads the retrieved passages and generates a direct, grounded answer — with the source document available for citation.
The answer is only as good as what was retrieved. Which is exactly the point. You are no longer asking the model to guess from training memory. You are handing it the right page and asking it to read.
💡 For Developers: Under the Hood
The embedding model does the heavy lifting in data preparation and retrieval—it must be the same model for both ingestion and retrieval, otherwise the vector spaces won’t align.
- Good free choices: nomic-embed-text via Ollama runs locally at no cost; text-embedding-3-small from OpenAI is excellent and cheap at scale.
- Vector storage: Supabase with the pgvector extension is the cleanest free-tier option if you’re already on Postgres — no separate infrastructure, no new service to manage.
Retrieval uses cosine similarity: vectors that point in the same mathematical direction are semantically similar. The final system prompt constraint — “answer only from the context below” — is non-negotiable. Without it, the model blends retrieved content with training memory and you lose the grounding benefit entirely.
🛠️ How this looks applied to MEMIS:
Instead of abstract concepts, imagine a technician uploading all equipment PDFs. The system parses them by heading, chops them into sections, and tags each chunk with metadata (equipment category, manufacturer, model number, facility). The vectors are stored in Supabase pgvector.
When a technician asks, “What is the safe operating pressure for the Getinge 88 series autoclave?”, the system bypasses keyword matches, pulls the exact paragraph from the manufacturer’s service manual, and the LLM formats a clean, direct answer with the document and page cited. The whole query takes under two seconds.
RAG vs Fine-Tuning: The Question You Will Get Asked
If you start talking about RAG with developers who have read about LLMs, someone will say: “why not just fine-tune the model on your documents?” It is a reasonable question with a clear answer.
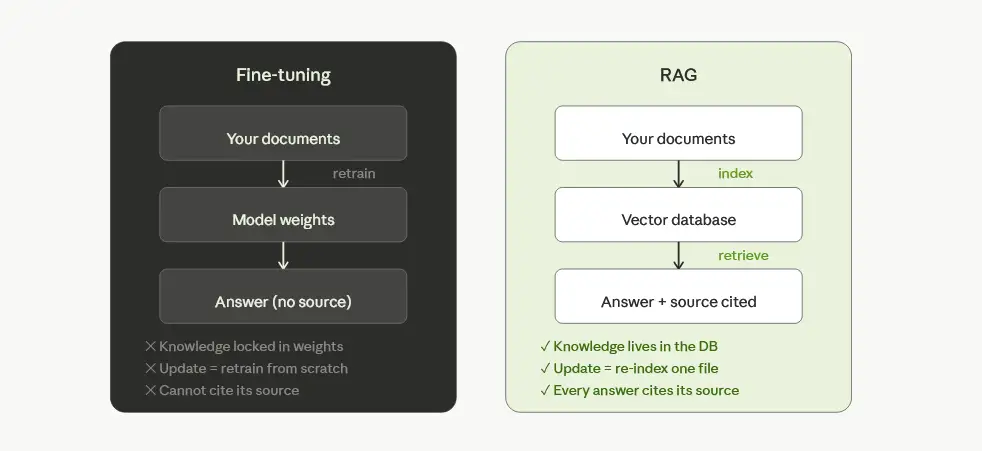
Fine-tuning bakes knowledge permanently into the model’s weights. You retrain the model on your data, and it learns from it at a deep level. This sounds powerful, and in some narrow cases it is — but for document question-answering it is almost always the wrong tool.
- It is expensive and rigid: It requires ML infrastructure, expertise, and time.
- It gets outdated instantly: The moment a document is updated, your fine-tuned model is wrong. You would need to retrain every time a manual is revised, a regulation changes, or a new piece of equipment is added to the inventory. In a system like MEMIS, where manufacturers issue firmware updates and service bulletins regularly, that would be a continuous and costly problem.
RAG sidesteps all of this. The knowledge lives in the database, outside the model. Update a document, re-index it, and the system reflects the change immediately. No retraining. No downtime. No ML budget.
There is one more thing fine-tuning cannot do that RAG can: cite its source. When a biomedical technician gets an answer, they need to know which manual it came from and which section confirms it. Fine-tuning buries that provenance inside model weights. RAG surfaces it with every answer.
For the vast majority of organisations with document-heavy knowledge bases, RAG is cheaper, faster, more maintainable, and more trustworthy than fine-tuning.
When You Actually Need RAG — and When You Don’t
This is the section most RAG explainers skip. Here is the honest version.
You definitely need RAG if:
- Your data is proprietary or locked away: You have a large set of internal documents the LLM was never trained on — policies, manuals, project reports, legislation, contracts.
- Your information has a tight shelf-life: The data changes frequently and needs to stay current without the lag and cost of retraining.
- The answer must be traceable: In medical, legal, or government contexts, “here is the source paragraph” is not optional. It is the whole point.
- You’re hunting across a massive library: Users need to query across hundreds of documents at once to solve a puzzle, like: “which of our 300 equipment manuals mentions error code E-04?”
Save your time and skip RAG if:
- You have fewer than twenty short documents: Just paste them directly into the prompt window. Context stuffing is simpler, works fine at small scale, and requires zero infrastructure.
- The LLM already knows your domain: Asking an LLM about standard Python syntax or common historical facts does not need a vector database behind it.
- A simple search handles it: Do not build a complex RAG pipeline to answer questions that Ctrl + F could handle in five seconds.
- You need live, ticking data: RAG retrieves from a static index. For current stock prices, live sensor readings, or today’s breaking news, use tool calls or direct API integrations instead.
The Honest Summary: RAG solves a specific problem very well. It is not a general upgrade to every LLM use case. Use it when your bottleneck is knowledge retrieval from a large, specific, changing document base. Don’t reach for it just because it is the technology people are talking about.
How to Build It: The Practical Starting Point
If you want to build this completely for free, the open-source stack requires no paid services: Ollama for local embeddings, Supabase with pgvector for the vector store, n8n for orchestration, and Groq for rapid generation. Total infrastructure cost: zero.
If you want a managed option: OpenAI embeddings with Supabase and either LangChain or LlamaIndex for the retrieval pipeline. Cost at moderate usage amounts to cents per query.
For a MEMIS-type deployment specifically, the key addition is metadata tagging at ingest time — equipment category, manufacturer, model, facility name. This lets retrieval be scoped: “search only manuals for Mindray equipment” or “only documents relevant to Kamuzu Central Hospital.” Without that scoping, a query about one autoclave model might surface results from a completely different manufacturer’s manual. Metadata filtering is what takes a RAG prototype and makes it production-ready.
A step-by-step build of the full stack — Supabase pgvector, n8n orchestration, and Groq generation — is in the RAG tutorial on AgentLabs. If you want to understand the agent layer that typically sits on top of a RAG system, the AI agents explainer is the right place to start.
One Final Thought
The MEMIS project showed me that the bottleneck in knowledge-heavy systems isn’t the data — organisations like the Ministry of Health have more data than they know what to do with. The bottleneck is retrieval. RAG solves exactly that. And today, it takes an afternoon to build the first version.
Gomezgani Walumbe is a software engineer and AI consultant based in Lilongwe, Malawi. He builds AI agents, RAG systems, and data infrastructure for NGOs, government, and international development organisations across the SADC region. Follow along at AgentLabs or on YouTube.
